PPG 情绪识别:几条路线的取舍与实测
写在前面
这个工作并不算solid,目前正在数据收集和实测阶段,涉及的数据集也只有WESAD和DEAP,并没有很强的参考意义,请谨慎参考。
摘要
要解决的问题很简单:在手表侧只有 PPG 和三轴加速度这两类输入的前提下,能不能先估计 valence 和 arousal,再映射到 Russell 情绪模型中的象限和离散标签,从而形成一条可闭环的情绪识别链路。
当前项目一共走过三条路线。第一条是 XGBoost Feature Baseline,它使用 HRV + ACC + SQI 这类手工特征,目标是先把任务跑通,并给后续复杂模型提供一个稳定参照。第二条是 EMCNN PPG-only,它直接建模单通道 PPG 波形,是当前的默认主方案。第三条是 EMCNN + aux,在 EMCNN 的基础上再加入 ACC/SQI 辅助输入,作为实验增强路线。
在当前 WESAD LOSO 实测下,EMCNN PPG-only 是综合表现最好的方案:它同时超过了 XGBoost 基线,并且比 EMCNN + aux 保持了更好的连续回归误差。EMCNN + aux 虽然在分类指标上更强,但 VA MAE 更差,更像分类增强方案。除此之外,本文还补充了推理性能、CPU/GPU、并发、内存和显存开销的实测,目的是把“能不能识别”和“值不值得部署”放在同一张桌子上讨论。
本文不公开项目实现和数据实测,仅作交流学习。
这个工作并不算solid,目前正在数据收集和实测阶段,涉及的数据集也只有WESAD和DEAP,并没有很强的参考意义,请谨慎参考。
一、这件事到底在做什么
当前项目的目标不是做一个泛泛的“情绪分类器”,而是要在手表侧有限传感器条件下,建立一条可以闭环的 Russell 情绪建模链路。输入是 PPG + ACC,中间层输出是连续的 valence 和 arousal,最后再映射到 Russell 情绪模型中的象限和离散标签。当前仓库中的推理接口已经对应到了这条链路:
- 连续层:
valence / arousal - 决策层:
quadrant - 展示层:
21个 Russell 标签 +Top-3
这里有一个必须讲清楚的前提:当前项目并不预设 PPG 能直接“表达情绪”,也不假设 PPG 和 valence/arousal 之间存在简单、稳定、显式的一一对应关系。更稳妥的说法是,情绪状态会通过自主神经系统影响心率、血管张力、外周循环和节律变化,而 PPG 恰好能观测到这些变化的一部分。因此,当前项目真正检验的是这样一个工程假设:PPG/ACC 中可能存在与 valence/arousal 相关的可学习统计模式。如果这个假设成立,就有机会在手表侧形成一套弱侵入、持续性的情绪状态估计能力。
当前输入约束也很明确:
- 加速度传感器:
1g / 512lsb PPG:250 Hz- 手表侧数据包长度:每组数据约
180 s
这些约束决定了项目不可能走高维、多模态、重设备路线,也不适合依赖脑电或摄像头。方法选择从一开始就必须兼顾可实现性、可解释性和后续部署成本。
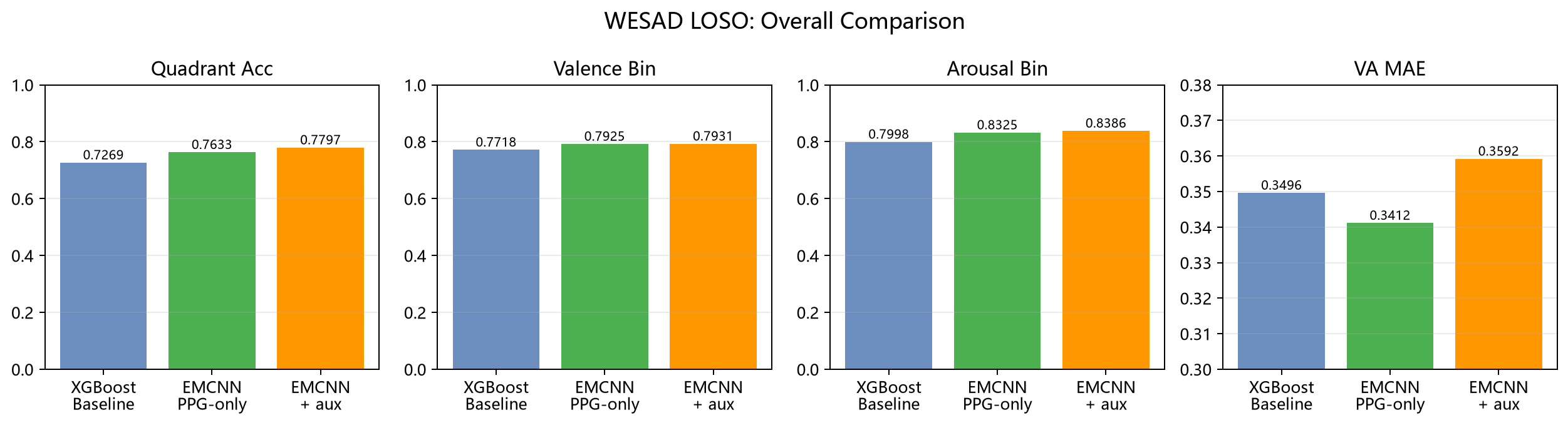
图1 三条方案总体结果对比。横向比较 XGBoost Feature Baseline、EMCNN PPG-only 和 EMCNN + aux 在 WESAD LOSO 下的核心指标表现。
二、看过什么,最后为什么选到这条路
当前方法不是凭空长出来的,而是从三篇关键论文一路收敛出来的。
第一篇是 An emotion recognition method based on frequency-domain features of PPG。这篇文章的价值不在于它给了一个可直接复刻的最终模型,而在于它很明确地说明了一件事:PPG 的信息量不只体现在传统 PRV/HRV 上,频域结构、谐波关系和功率分布本身也可能携带与情绪相关的统计模式。它通过双 Windkessel 模型解释 PPG 频谱,再把频域特征交给 SVM 做高低 arousal/valence 区分。对当前项目来说,这篇论文最大的启发是:如果单通道 PPG 已经有一定可分性,那么先做一版“手工特征 + 轻量模型”的可解释基线是合理的。这也是为什么后面会先做 XGBoost Feature Baseline。
第二篇是 Emotion Recognition Using PPG Signals of Smartwatch on Purpose of Threat Detection。它的价值更多在现实层面。它不是 Russell 情绪识别,而是面向真实手表和短时 PPG 的 threat detection。它用了 GMM 去过滤模糊标签,用 1D-CNN 在短窗口上做二分类。这篇论文最有用的地方是提醒我们:手表场景真的很脏,低成本光学传感器、短窗口、运动伪影、标签不干净这些问题都会直接影响结果。对当前项目来说,这篇论文没有直接给出主方法,但它很强地强化了一个判断:如果这条路要做成真实工程,信号质量和标签质量迟早都得正面处理。
第三篇是 EMCNN。这篇论文和当前项目的主问题最接近。它只用单通道 PPG 做情绪识别,并且不满足于简单二分类,而是进一步考虑 valence、arousal 以及四象限细粒度任务。它的核心想法是:单通道 PPG 信息弱,所以直接喂一个普通网络不一定够,要用多分支、多尺度的方式同时看原始波形、平滑波形和下采样波形。对当前项目来说,前两篇更多是在回答“这条方向值得做、现实里会遇到什么问题”,而 EMCNN 真正回答的是“如果要把单通道 PPG 这条主线做强,网络结构上可以怎么做”。这也是为什么当前项目最后不是停留在特征路线,而是把 EMCNN 落成了主方案。
如果把三篇文章放在一起看,它们的作用大致可以概括成三句话:
- 频域特征论文告诉我们:
PPG本身值得做,而且手工特征路线有意义。 - 手表威胁检测论文告诉我们:真实穿戴场景下,噪声、运动和标签问题不能忽视。
EMCNN告诉我们:如果要把单通道PPG主线继续做强,波形级建模是一条更值得押注的方向。
三、我在这个项目里实际做了什么
这部分很重要,因为如果只讲论文和结论,不把你真正做过的事情写出来,整篇文章就会变成“看过几篇论文后的感想”。当前项目里真正做过、并且已经进到代码和实测层面的工作,大致有下面这些。
第一,建立了一条完整可跑通的 XGBoost Feature Baseline。这条线不是某篇论文的严格复现,而是一个项目内部构建的工程基线。它使用 HRV + ACC + SQI 这组结构化特征,在 WESAD 上做 LOSO 训练和验证,目的是先把任务打通,并给后续复杂模型提供一个稳定、可解释、低复杂度的参照物。
第二,把 EMCNN 从论文思路落到了当前仓库里,而且不是单纯把网络结构抄过来,而是把它接进了当前项目自己的数据、标签、评估协议和推理接口里。也就是说,当前的 EMCNN 不是“论文 demo”,而是已经变成了仓库内可训练、可评估、可推理的正式方案。
第三,把 EMCNN 分成了两条实测路线:
EMCNN PPG-onlyEMCNN + aux
前者是当前主方案,后者是加入 ACC/SQI 辅助输入后的实验增强方案。这样做的目的,是把“纯波形建模能力”和“多模态辅助是否有额外价值”分开看,而不是把所有改动糊成一个黑盒。
第四,围绕当前仓库做了多轮实测,不只看识别效果,还补了 CPU/GPU、并发、内存和显存的推理评估。这样得到的不是单一“准确率最高”的方法,而是一组更接近真实工程的判断:哪条路线综合效果更好,哪条路线更轻量,哪条路线更适合 CPU,哪条路线更适合 GPU,多实例时资源压力到底怎样。
第五,对仓库结构做了重组,把当前方法组织成“主方案 / 对照方案 / 实验增强方案”的形式,而不是简单按历史版本堆文件。现在仓库里这三条路线的角色已经比较清楚:
XGBoost Feature Baseline:轻量、可解释、CPU 友好,对照方案EMCNN PPG-only:综合最优,当前默认主方案EMCNN + aux:分类增强,实验路线
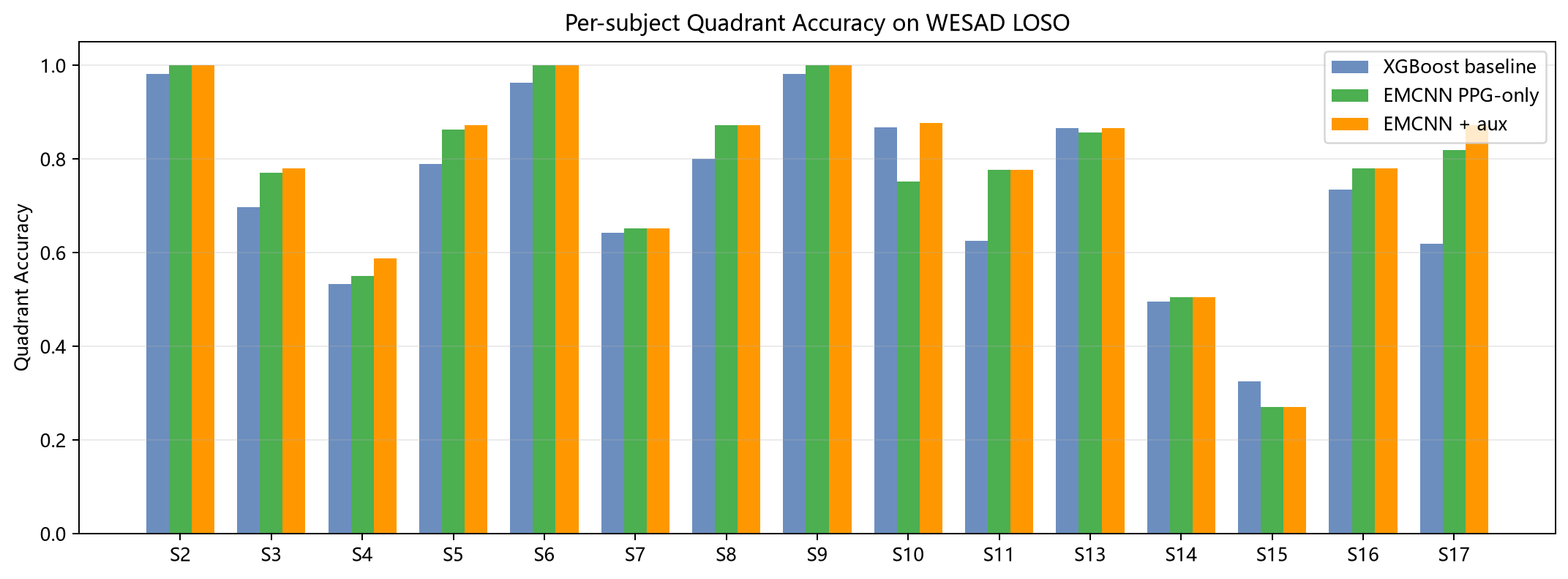
图2 按被试的象限准确率对比。展示三条方案在不同被试上的 quadrant accuracy 差异,用于观察哪些被试更容易、哪些被试更困难。
四、数据、协议和这件事的边界
当前阶段选择 WESAD 不是因为它完美,而是因为它在公开数据集里足够实用。它提供了腕部 BVP/PPG 和加速度信号,有标准化数据格式,也有情绪/压力相关标签,因此非常适合作为第一阶段验证“这条路线能不能跑通”的公共入口。
但 WESAD 也有几个必须写在前面的限制。第一,它的腕部 BVP 虽然和手表 PPG 在大方向上相似,但并不是同一个东西。设备、采样链路、佩戴方式、运动状态和噪声分布都不一样。第二,WESAD 主要是实验室静坐场景,不是日常佩戴场景。第三,也是最重要的一点,它的 SAM 评分本质上是条件级标签,不是逐窗标签。同一条件下切出来的很多窗口共享同一对 valence/arousal 标签,这意味着当前实验更像是在检验“在这些条件下是否存在可学习统计模式”,而不是严格检验“模型能否逐窗跟踪真实细粒度情绪波动”。
当前主评估协议是 LOSO,也就是留一被试交叉验证。选这个协议的原因很直接:样本级切分太容易带来信息泄漏,而 LOSO 更接近“跨人泛化”的问题设定。当前主要看四个指标:
quadrant_accuracyvalence_binary_accuracyarousal_binary_accuracyva_mae
前面三个更偏离散决策能力,最后一个更偏连续 Russell 坐标准确性。这四个指标放在一起,比较能看清“一个模型到底更会分类,还是更会回归”。
在这里还需要补一个当前项目里非常关键、但前面一直默认读者已经知道的背景:为什么整个系统最后会落到 Russell 情绪模型上。
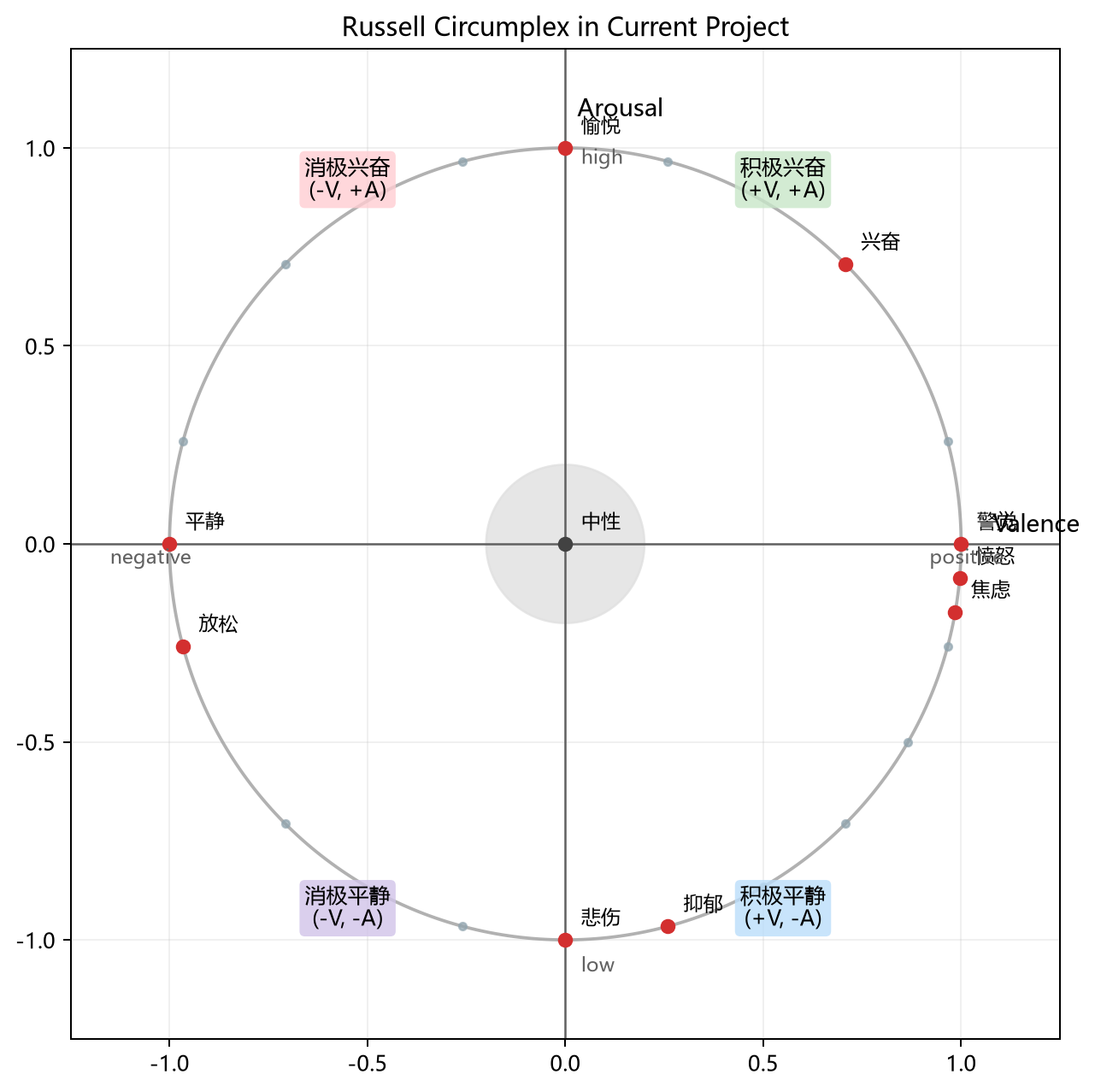
图3 Russell 情绪模型在当前项目中的二维坐标表示。横轴为 valence,纵轴为 arousal,中心圆为中性区,外围示意了当前项目中若干典型离散标签的位置。
Russell 的 circumplex model 可以把情绪看成一个二维空间,而不是一组完全离散的情绪类别。这个二维空间的两个轴分别是:
valence:情绪是更偏正向还是负向arousal:情绪是更偏激活还是平静
这样一来,情绪不再只是“开心”“生气”“难过”这种硬标签,而是先落在一个连续坐标平面上。比如同样是正向情绪,高 valence + 高 arousal 更接近兴奋、愉悦,高 valence + 低 arousal 更接近平静、放松;同样是负向情绪,低 valence + 高 arousal 更接近焦虑、愤怒,低 valence + 低 arousal 更接近低落、无力。这种表达方式有两个明显好处:第一,它比纯离散分类更细,允许模型输出带有程度感的结果;第二,它天然适合做后续映射,无论最后想落到四象限、五类状态还是更细的离散标签,都可以从同一个二维坐标出发。
当前项目正是沿着这个思路设计的。模型本身不直接预测“开心”“悲伤”这种名字,而是先回归两个连续量:valence 和 arousal。随后再由 RussellEmotionModel 做两步映射。
第一步是从二维坐标映射到象限。当前项目里使用的是“中心中性区 + 四象限”的方式:
valence > 0, arousal > 0:积极兴奋valence < 0, arousal > 0:消极兴奋valence < 0, arousal < 0:消极平静valence > 0, arousal < 0:积极平静- 距离原点足够近:中性
这一步的好处是把连续坐标压成一个稳定、容易解释的决策层输出。也就是说,即使后面的细粒度标签还存在不确定性,系统至少先能给出一个大方向判断,比如“当前更像高唤醒的正向状态”还是“更像低唤醒的负向状态”。
第二步是从二维坐标进一步映射到 21 个离散 Russell 标签。当前仓库里做法不是重新训练一个 21 类分类器,而是给每个标签预先定义一个坐标点,然后根据预测得到的 (valence, arousal) 去计算与这些标签点的相似度或距离,选出最接近的标签,并给出 Top-3 候选。这种做法在工程上很实用,因为它把“连续估计”和“离散展示”分开了:模型负责学连续空间,标签系统负责做解释层映射。这样既保留了二维情绪模型的连续性,又能给最终界面一个更直观的名字。
如果把这一步说得再直白一点,就是:模型先在二维平面上给出一个点,然后 Russell 模型再问“这个点离哪些情绪名称最近”。例如,一个点如果落在右上区域,说明它同时偏正向、偏高唤醒,那么就更可能被映射到“兴奋”“愉悦”“警觉”这一带;如果落在右下区域,就更可能被映射到“平静”“放松”;如果落在左上,则更接近“焦虑”“愤怒”;如果落在左下,则更接近“悲伤”“抑郁”。这也是为什么当前项目最终既能给出一个连续的 (valence, arousal),又能顺势落到一个更像人类语言的情绪标签上。
从方法论上看,这也解释了为什么当前项目没有一上来就把任务定义成多类情绪分类。直接做多类分类当然可以,但那样会把“标签定义方式”和“模型表达能力”绑死在一起。现在这套 Russell 路线的优点是:
- 底层模型学的是连续情绪维度
- 中间层可以统一比较不同方法对
valence/arousal的拟合能力 - 上层既能输出象限,也能输出更细的离散标签
换句话说,Russell 模型在当前项目里不只是一个结果展示工具,它其实是整个任务定义的骨架:它决定了为什么模型输出不是直接的情绪名称,为什么当前评估既有二分类准确率也有 VA MAE,以及为什么 EMCNN PPG-only 和 XGBoost baseline 虽然内部结构不同,但最后仍然可以在同一套坐标系里公平比较。
五、结果:三条路线到底谁更好
1. 识别效果
当前三条方案在 WESAD LOSO 下的主结果如下:
| 方法 | 角色 | Quadrant Acc | Valence Bin Acc | Arousal Bin Acc | VA MAE |
|---|---|---|---|---|---|
XGBoost Feature Baseline | 对照方案 | 0.7269 | 0.7718 | 0.7998 | 0.3496 |
EMCNN PPG-only | 当前主方案 | 0.7633 | 0.7925 | 0.8325 | 0.3412 |
EMCNN + aux | 实验增强 | 0.7797 | 0.7931 | 0.8386 | 0.3592 |
这个结果非常有代表性,因为它把三条路线的差异说得很清楚。
从整体结果图里可以直接看到一个很清楚的趋势:EMCNN PPG-only 在三项主要识别指标上都稳定超过了 XGBoost baseline,而 EMCNN + aux 又把分类指标进一步往上推了一点,但代价是 VA MAE 回退。
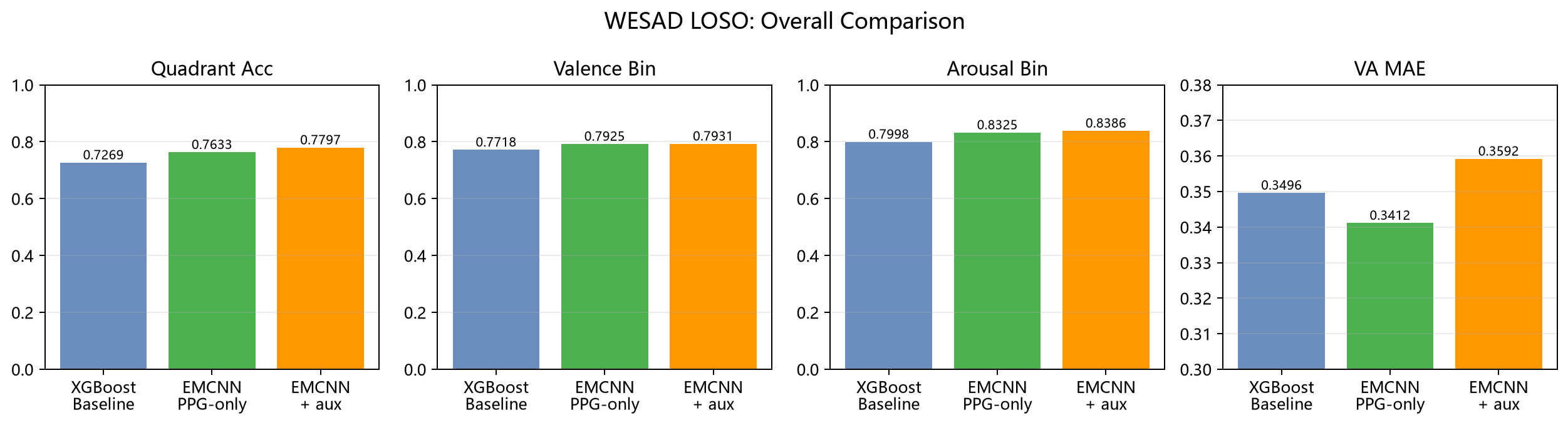
图4 三条方案总体结果对比。用于在结果章节再次强调三种方案在分类指标和 VA MAE 上的整体取舍。
XGBoost baseline 的意义首先在于,它证明了任务本身是可做的。也就是说,即使只用手工特征和树模型,也已经能从 PPG/ACC 里学到一些与 valence/arousal 有关的可预测模式。但它并不是最优方案。
EMCNN PPG-only 是当前综合表现最好的方案。它不但在三项分类指标上超过了 XGBoost baseline,而且 VA MAE 也更低。这说明端到端波形建模确实从原始 PPG 里学到了手工特征没有完全覆盖的表示,因此它成为当前默认主方案是有实测依据的。
EMCNN + aux 的特点也很明确:它在分类指标上是三者中最高的,但 VA MAE 更差。这说明辅助输入对于“分对类”是有帮助的,但并不自动等于 Russell 连续坐标更准。换句话说,它更像一条分类增强路线,而不是当前综合最优路线。
2. 结果说明了什么
当前最稳妥的结论不是“PPG 可以直接表达情绪”,而是:在现有 WESAD LOSO 协议下,PPG 波形中确实存在可被学习并用于预测情绪维度的统计模式,而且多分支波形建模比单纯的手工特征路线更能挖出这些模式。进一步说,EMCNN PPG-only 的优势说明,原始波形里的信息并没有被 HRV + ACC + SQI 这套手工摘要完全吃干净。
3. 结果不能说明什么
同样重要的是,当前结果不能被过度解释。它不能直接证明“PPG 与情绪存在一一对应的直接关系”,因为模型学到的只是当前数据和标签协议下的可预测模式。它不能直接外推到真实日常佩戴场景,因为 WESAD 与真实手表环境差距很大。它更不能被理解成对情绪生理机制本身的最终证明。这里的模型更像是在检验“数据里有没有可利用的信息”,而不是在给出生理学终局答案。
六、性能、并发和资源开销:值不值得部署
只看识别效果是不够的,因为当前项目最后一定会落到工程问题:如果方案更准,但太重、太吃显存、并发一上来就崩,那就只是论文好看。当前在真实手表 CSV 窗口上做过 CPU/GPU 与并发实测,输入窗口为首个 60 s 窗口,PPG 样本数约 15000,设备为 RTX 4070 SUPER。
1. 单次推理延迟
| 方法 | 设备 | Mean Latency | Throughput |
|---|---|---|---|
EMCNN PPG-only | CPU | 82.20 ms | 12.16 req/s |
EMCNN PPG-only | GPU | 62.66 ms | 15.96 req/s |
XGBoost Feature Baseline | CPU | 50.08 ms | 19.97 req/s |
XGBoost Feature Baseline | GPU | 46.06 ms | 21.71 req/s |
如果只看单次端到端推理,当前最快的是 XGBoost 路线,尤其 XGBoost GPU 在当前环境下略快于 CPU。EMCNN 放到 GPU 上也有收益,但由于整条链路里仍有很多 CPU 侧预处理和输入整理,它的端到端延迟并没有像纯网络前向那样大幅下降。
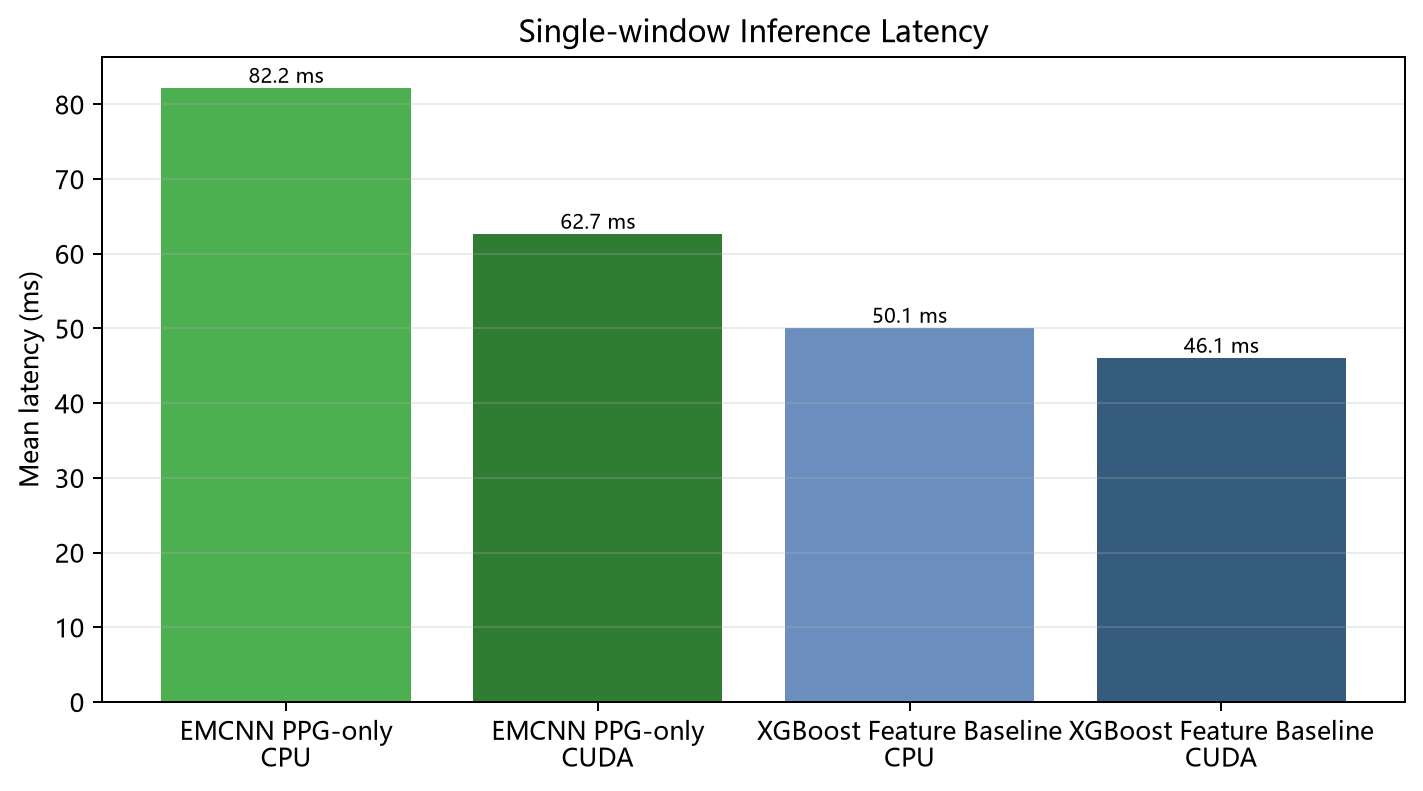
图5 单窗口推理延迟对比。比较 EMCNN PPG-only 与 XGBoost Feature Baseline 在 CPU/GPU 两种设备上的单次端到端推理平均延迟。
2. 并发吞吐
| 方法 | 设备 | 最佳 workers | 最佳吞吐 |
|---|---|---|---|
EMCNN PPG-only | CPU | 2 | 27.79 req/s |
EMCNN PPG-only | GPU | 8 | 20.03 req/s |
XGBoost Feature Baseline | CPU | 4 | 25.89 req/s |
XGBoost Feature Baseline | GPU | 4 | 25.59 req/s |
这组结果和前一轮只看速度的直觉不完全一样。当前这套更严格的带内存统计实测下,EMCNN GPU 的并发表现没有之前那轮纯速度测试那么激进,说明资源同步和测量方式对最终结果会有影响。更稳妥的判断是:
XGBoost在CPU/GPU下都比较稳,吞吐相对均衡EMCNN在CPU下并发上去以后延迟增长明显EMCNN GPU能吃掉一部分前向负担,但整条链路还是受 CPU 预处理影响
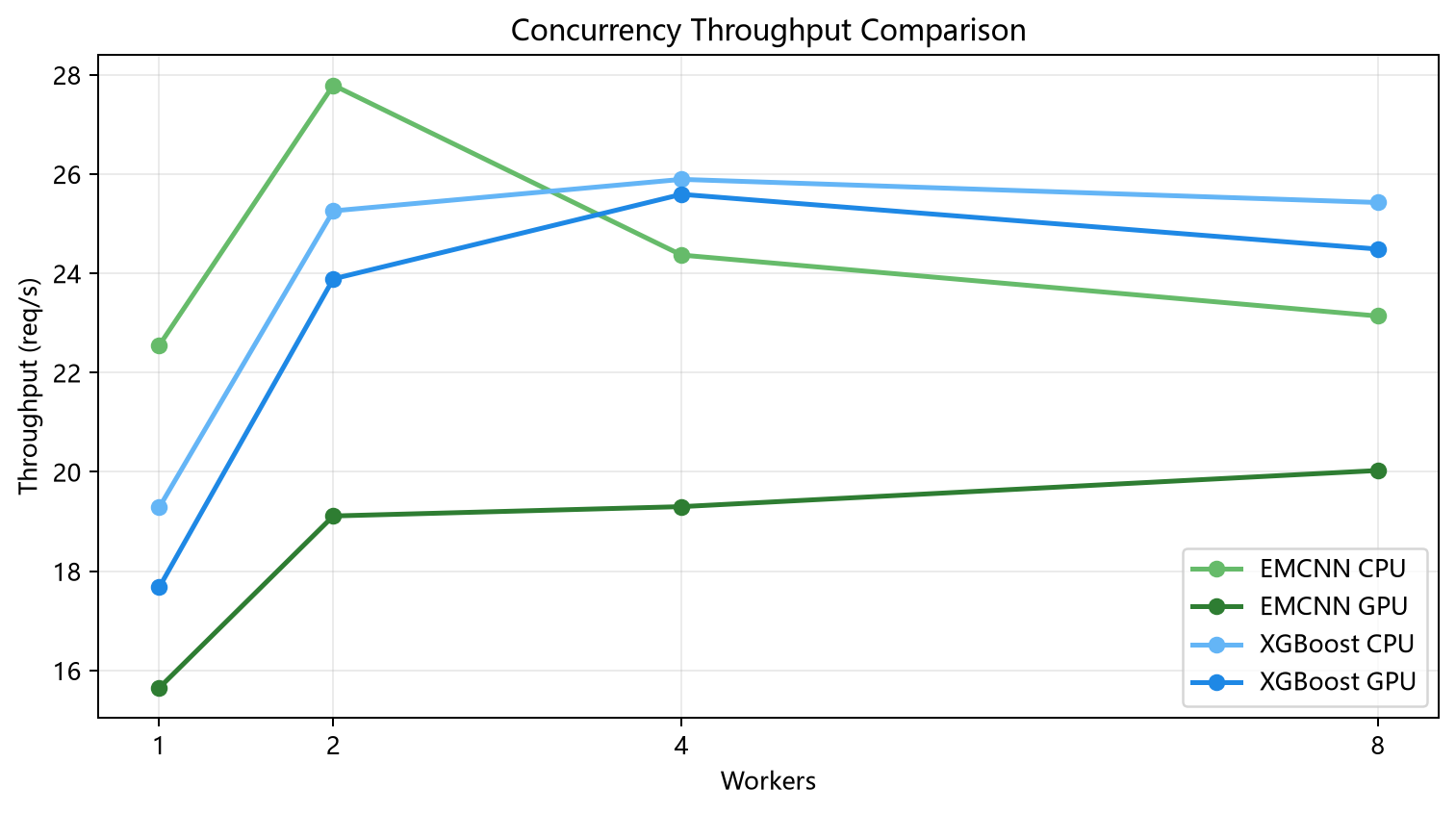
图6 并发吞吐对比。比较两条方案在不同 worker 数量下的吞吐变化,用于观察其并发扩展特性。
3. 内存与显存开销
单实例首次加载和 warmup 后的资源变化,大致如下:
| 方法 | 设备 | RSS 增量 | 显存变化 |
|---|---|---|---|
EMCNN PPG-only | CPU | +20.08 MB | - |
EMCNN PPG-only | GPU | +327.92 MB | 3373 -> 3431 MB |
XGBoost Feature Baseline | CPU | +18.09 MB | - |
XGBoost Feature Baseline | GPU | +15.52 MB | 3457 -> 3443 MB |
这里有两个很关键的工程结论。第一,EMCNN GPU 的主存和显存开销都明显高于 XGBoost。第二,XGBoost 即使启用 GPU,当前链路里的显存压力也很小,说明它的主要瓶颈并不在模型预测本身,而更多还是在预处理和特征提取上。
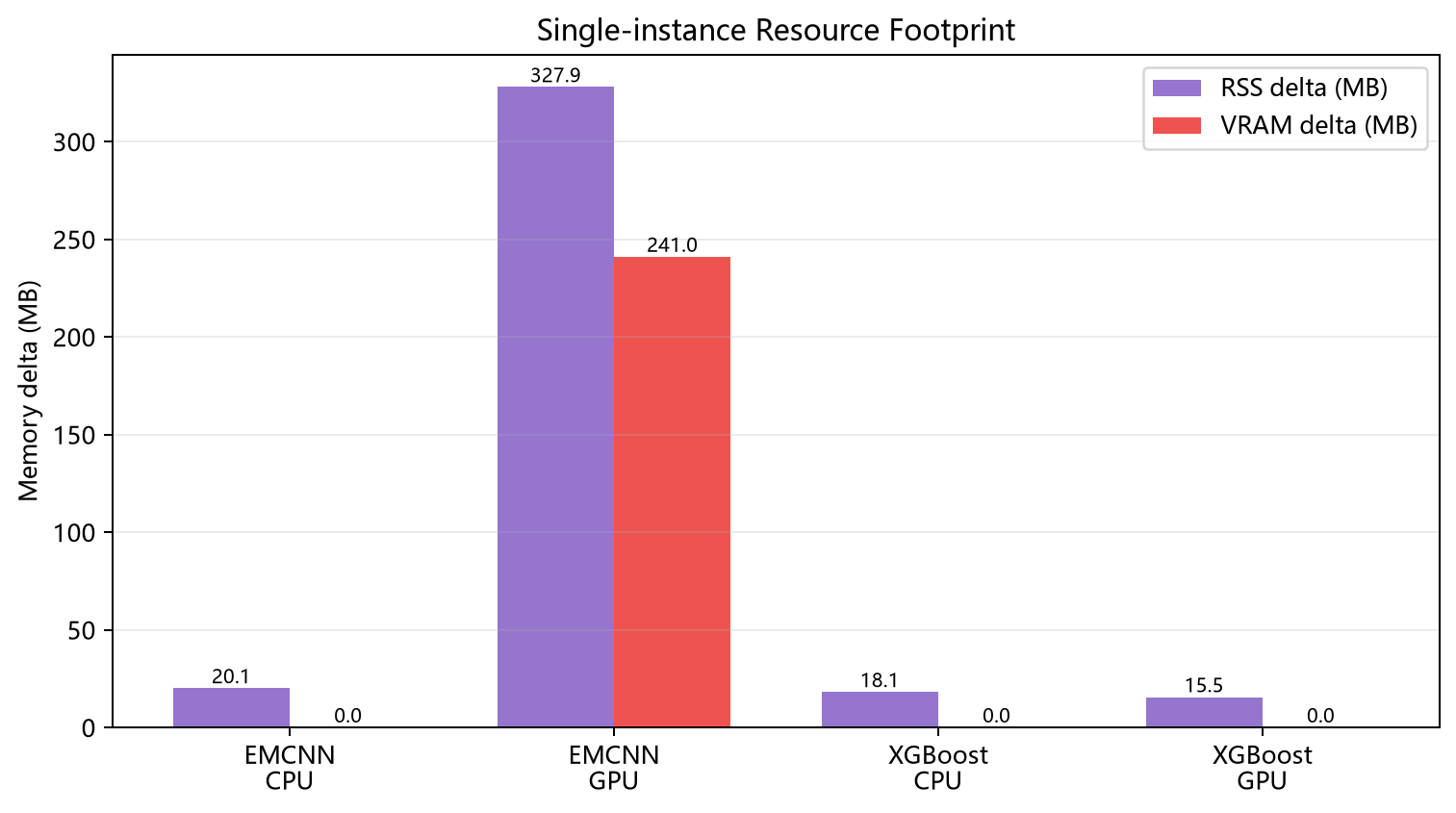
图7 单实例资源占用对比。展示两条方案在 CPU/GPU 下进行一次模型加载和 warmup 后的主存与显存增量。
4. 多实例同时开启时会怎样
如果考虑服务里同时开多个处理器实例,那么除了吞吐,还得看常驻占用趋势。当前同一进程内多实例测试的大致现象是:
EMCNN CPU:多实例RAM增量不算夸张,但会逐步增长EMCNN GPU:多开实例会逐步吃掉显存,虽然增长不是线性的,但确实存在常驻开销XGBoost:无论CPU还是GPU,多实例资源压力都更小
这意味着,如果以后服务架构是“每个 worker 一个独立模型实例”,那么 EMCNN 路线要更认真地规划显存水位和实例复用,而 XGBoost 会更适合大量轻量 worker 的 CPU 化部署。
5. 工程上的取舍结论
如果只看识别效果,当前主方案毫无疑问还是 EMCNN PPG-only。但如果把推理速度、并发吞吐、内存和显存一起考虑,结论会更细一些:
- 效果优先:
EMCNN PPG-only - 轻量与资源优先:
XGBoost Feature Baseline - 分类增强试验:
EMCNN + aux
也就是说,当前项目已经不是“谁最准就用谁”这么简单,而是已经进入了典型工程取舍阶段。
七、现在的问题和下一步
当前这套工作的局限其实已经比较清楚。最大的限制来自标签本身:WESAD 是条件级弱标签,这决定了当前实验的上限。第二个限制来自场景差距:实验室静坐 WESAD 和真实手表日常佩戴不是一回事。第三个限制来自被试差异,困难被试说明模型距离稳定泛化还有距离。第四个限制来自 aux 路线本身:目前它只是最基础的晚期融合,结构还很粗。
因此,下一步最合理的主线不是继续在低价值的小超参扰动上消耗时间,而是围绕现有结论往前推进:
- 继续以
EMCNN PPG-only作为当前主线,因为它已经证明了自己是综合最优方案。 EMCNN + aux不应该继续做同类小调参,而应该转向融合结构本身的改造,比如门控融合、残差融合,或者把SQI改成训练权重。- 增加被试级误差分析,尤其是去看困难被试到底为什么难。
- 引入真实手表数据做更贴近部署场景的验证。
如果把当前所有结果压成一句话,那就是:这件事不是已经做成了,但已经从“值不值得做”走到了“哪条路线更值得继续做”。而现在最值得继续往下做的,仍然是 EMCNN PPG-only。
附:三篇 related 文章的简短笔记
A. Frequency-domain features of PPG
- 关键词:频域特征、双 Windkessel、生理解释、
SVM - 最大价值:证明
PPG的频域结构是有信息量的,不应该只盯着PRV - 对本项目的真正启发:先做一版可解释、结构化特征基线是合理的
- 为什么没直接照搬:特征工程偏重,且目标更接近二分类区分,不是当前主线
B. Smartwatch Threat Detection
- 关键词:真实手表、短时
PPG、低质量标签、GMM过滤、1D-CNN - 最大价值:提醒手表场景的真实难点主要在噪声、运动伪影和标签不干净
- 对本项目的真正启发:真实可穿戴场景必须认真面对信号质量与标签可靠性
- 为什么没直接照搬:任务更偏 threat detection,不是 Russell 两维连续建模
C. EMCNN
- 关键词:单通道
PPG、多分支、多尺度、细粒度情绪识别 - 最大价值:给出一条把单通道
PPG做强的明确路线 - 对本项目的真正启发:把“PPG 值得做”推进到了“PPG 可以怎么做强”
- 为什么最后成了主线:它最接近当前项目的核心目标,而且在当前
WESAD LOSO实测中确实跑赢了 baseline